For Shoppers
For Business
Fit Intelligence Platform
Platform Overview
Conversational Fit Agent
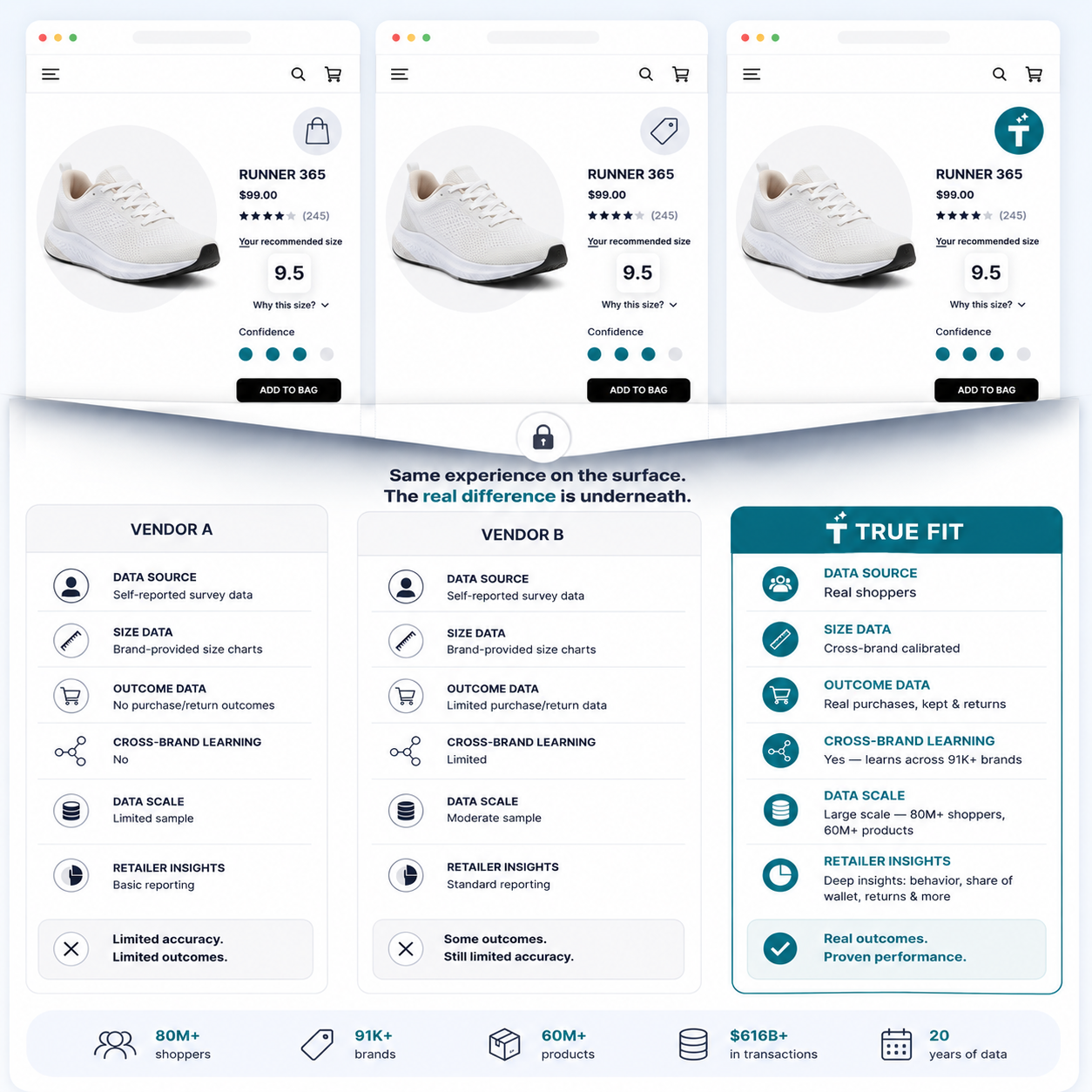
Fit Intelligence Layer
Integrations & Technology
How it works
Technology Partners
Shopify Integration
Resources
Case Studies
Guides & Reports
Blog
Ready to get started?
Get a Demo
About True Fit
Careers
Support
Get a Demo
True to You Blog
Blog
July 7, 2026
True Fit Named One of Built In’s 2026 Best Startups to Work For in Boston
Blog
July 1, 2026
How Apparel Brands Can Build AI Shopping Agents That Don’t Guess on Fit
Blog
June 24, 2026
Why Apparel Shoppers Abandon Their Cart, and Why Discounting Is the Wrong Fix
Blog
June 16, 2026
Will This Actually Fit Me? Jessica Murphy on Why AI Shopping Agents Need Fit Intelligence
Blog
June 4, 2026
PDP Size Guidance vs. Fit Intelligence
Blog
May 21, 2026
Fashion ecommerce conversion rate benchmarks: what good actually looks like
Blog
May 8, 2026
How fit recommendation technology works: what to look for when evaluating platforms
Blog
May 6, 2026
How Fit Finder Tools Work (And What Separates Good From Bad)
Blog
April 30, 2026
What Is Digital Fitting? How Retailers Are Using It to Convert More and Return Less
Blog
April 21, 2026
Why your ecommerce return rate won't budge, and the hidden behavior driving it
Blog
February 17, 2026
True Fit Launches the First AI Shopping Agent Built on 20 Years of Real Fit Data
Blog
February 17, 2026
True Fit Launches Agentic Commerce Fit Agent on Retailgentic Podcast
Blog
June 25, 2024
Tech-Driven Trends: How AI is helping us get dressed.
Blog
May 21, 2024
When Everybody has Access to AI, Unique Proprietary Data Sets will be the Biggest Differentiator
Blog
May 21, 2024
True Fit: The Digital Fitting Tool Driving 900% Growth on Shopify
Next





.png)





.png)
.png)
.png)